
在当今数字化浪潮的推动下,互联网应用的规模与复杂度呈指数级增长。从支撑亿级用户的社交平台,到处理海量数据的电商平台,再到实时响应的金融交易系统,传统的单体架构(Monolithic Architecture)早已无法满足现代应用对高并发、高可用、可扩展、易维护的核心诉求。在这样的背景下,“分布式”(Distributed)与“集群”(Cluster)这两个概念应运而生,成为构建现代大型软件系统的基石。然而,这两个术语常常被混淆,甚至被当作同义词使用。本文将结合多篇权威技术文章的见解,从基本概念、核心原理、关键技术、典型架构、挑战与解决方案等多个维度,为您系统性地剖析分布式与集群的奥秘,带您从理论走向实践。
第一章:开篇明义——分布式与集群的本质
要理解分布式与集群,我们首先要明确它们的定义,并通过一个生动的比喻来建立直观认知。
1.1 核心定义
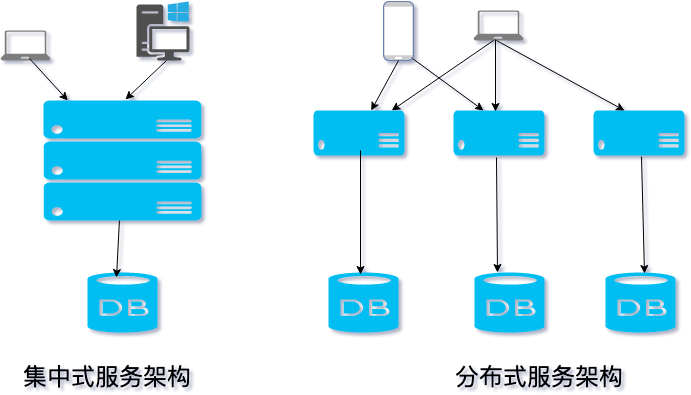
- 集群 (Cluster): 集群是指将同一个应用或服务部署在多台物理或虚拟服务器(节点)上,这些节点共同对外提供服务,形成一个逻辑上的整体。集群的核心目标是实现负载均衡(Load Balancing)和高可用性(High Availability, HA)。集群中的所有节点通常功能完全相同,它们处理的是同质化的请求。当一个请求到达时,可以通过负载均衡器(如Nginx、LVS)将其分发到任意一个健康的节点上进行处理。如果某个节点发生故障,其他节点可以无缝接管其工作,从而避免服务中断。

- 分布式 (Distributed): 分布式是指将一个庞大的、复杂的整体业务系统,按照一定的原则(如业务领域、功能模块)拆分成多个独立的、可自治的子系统或服务,这些服务部署在不同的服务器上,彼此之间通过网络进行通信和协作(如RPC、消息队列),最终共同完成整个业务流程。分布式的核心思想是解耦(Decoupling)和专业化分工。它将一个“大问题”分解为多个“小问题”,让每个服务专注于解决一个特定的领域问题。
1.2 经典比喻:小饭店的进化史
一个经典的“小饭店”比喻能帮助我们快速抓住两者的精髓:
- 初始状态(单体架构): 饭店里只有一个全能厨师,他需要负责从洗菜、切菜、配菜、炒菜到上菜的所有环节。这就像一个传统的单体应用,所有功能模块都紧密耦合在一个代码库和一个进程中。
- 问题出现: 随着顾客增多,一个厨师忙不过来,出菜速度变慢,成为瓶颈。
- 集群化(Scale Out): 为了解决“炒菜”环节的压力,老板请了第二个、第三个厨师,他们都和第一个厨师一样,能独立完成“炒菜”任务。现在,当有炒菜订单时,三个厨师可以并行工作,分担压力。这就是集群——多个人做同一件事。它提升了处理能力(性能)和容错能力(高可用)。
- 分布式化(Decomposition): 为了让主厨能更专注于“炒菜”,老板又请了一位专门的配菜师,负责洗菜、切菜、备料。主厨只需要专注于烹饪。配菜师和主厨是两个不同的“服务”,他们需要协同工作:配菜师准备好食材后,通知主厨;主厨炒好菜后,再交给服务员上菜。这就是分布式——多个人做不同的事。它通过分工协作,提高了整体效率和专业性。
1.3 核心区别总结
| 维度 | 集群 (Cluster) | 分布式 (Distributed) |
|---|---|---|
| 核心思想 | 复制 (Replication) - 横向扩展 | 分解 (Decomposition) - 职责分离 |
| 目标 | 提升性能(吞吐量)、实现高可用、负载均衡 | 解耦业务、提升可扩展性、可维护性、灵活性 |
| 节点角色 | 同质化:所有节点运行相同的代码,功能完全相同。 | 异质化:不同节点运行不同的服务,功能各不相同。 |
| 工作模式 | 并联:节点独立处理请求,互不依赖。 | 串联/协同:节点间需通信、调用、传递数据。 |
| 通信需求 | 节点间基本无需直接通信,主要与负载均衡器交互。 | 节点间必须通过网络进行频繁的通信和协调。 |
| 复杂性 | 相对较低,主要是部署、监控和负载均衡策略。 | 相对较高,涉及网络、数据一致性、容错、监控等复杂问题。 |
| 典型代表 | Web服务器集群、数据库的只读副本集群。 | 微服务架构、SOA、Hadoop/Spark大数据平台。 |
一句话总结:集群是“量”的扩展,分布式是“质”的变革。
第二章:集群详解——高可用与负载均衡的基石
集群是实现系统高可用和应对高并发流量的最直接手段。本章将深入探讨集群的架构、关键技术和实现方式。
2.1 集群的核心目标
- 高可用性 (High Availability): 通过冗余部署,消除单点故障(Single Point of Failure, SPOF)。当集群中某个节点因硬件故障、软件崩溃或网络中断而宕机时,其他健康节点可以继续提供服务,确保业务不中断。通常用“几个9”来衡量可用性,如99.9%(一年宕机约8.76小时)、99.99%(一年宕机约52.6分钟)。
- 负载均衡 (Load Balancing): 将大量的客户端请求均匀地分发到集群中的各个节点上,避免单个节点过载,从而最大化整个集群的处理能力和资源利用率。
- 可扩展性 (Scalability): 当业务增长、流量增大时,可以通过简单地增加新的服务器节点(水平扩展,Scale Out)来提升系统整体的处理能力,而无需升级单台服务器的硬件(垂直扩展,Scale Up)。
2.2 集群的关键组件
一个典型的集群架构包含以下核心组件:
- 集群节点 (Nodes): 运行实际应用服务的服务器实例。在Web集群中,它们是运行Nginx、Tomcat、Node.js等的服务器;在数据库集群中,它们是运行MySQL、PostgreSQL等的数据库实例。
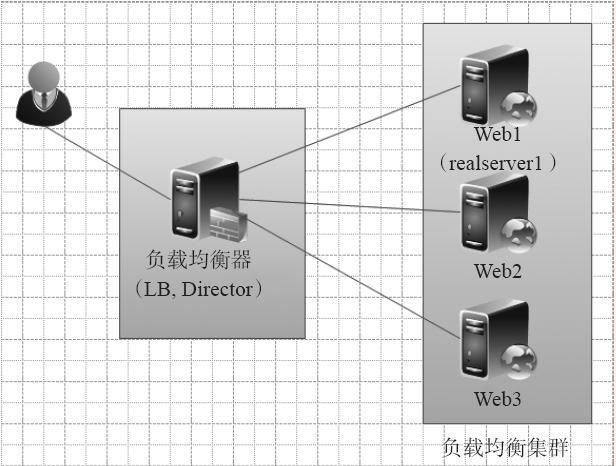
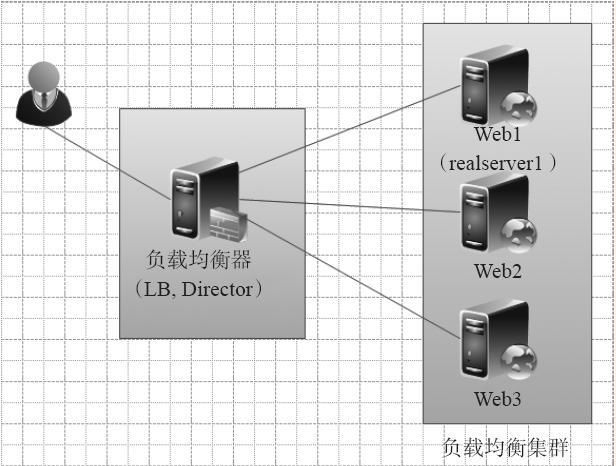
- 负载均衡器 (Load Balancer): 集群的“交通指挥官”。它接收来自客户端的所有请求,并根据预设的算法(如轮询、加权轮询、最少连接、IP哈希等)将请求转发给后端的某个节点。负载均衡器可以是硬件设备(如F5),也可以是软件(如Nginx、HAProxy、LVS),或是云服务商提供的服务(如AWS ELB、阿里云SLB)。
- 健康检查 (Health Check): 负载均衡器会定期向后端节点发送探测请求(如HTTP Ping、TCP连接),以判断节点是否存活和健康。如果某个节点连续多次检查失败,负载均衡器会将其从服务列表中移除,不再向其转发请求,直到它恢复健康。
- 共享存储 (Shared Storage, 可选但常见): 对于有状态的应用(如需要保存会话Session的应用),集群节点可能需要访问同一份数据。这通常通过共享存储(如NFS、分布式文件系统)或集中式缓存/数据库(如Redis、MySQL)来实现。
2.3 集群的部署模式
- 主-主模式 (Active-Active): 所有节点都处于活跃状态,共同处理请求。这是最常见的模式,如Web服务器集群。负载均衡器将请求分发给任意一个节点。
- 主-备模式 (Active-Standby): 只有一个主节点(Master)处理请求,其他节点作为备用(Slave/Standby)。当主节点发生故障时,通过故障转移(Failover)机制,将备用节点提升为新的主节点。这种模式常用于数据库集群(如MySQL主从复制),以保证数据一致性。
2.4 实战案例:Nginx + Tomcat 集群
一个经典的Web应用集群架构如下:
- 客户端请求首先到达Nginx服务器(作为负载均衡器)。
- Nginx通过
upstream配置定义了一个Tomcat服务器池(集群节点)。 - Nginx根据配置的负载均衡算法(如
round-robin),将HTTP请求转发给池中的某个Tomcat实例。 - Tomcat实例处理请求,生成响应并返回给Nginx。
- Nginx再将响应返回给客户端。
- Nginx定期对Tomcat实例进行健康检查,自动剔除故障节点。
此架构显著提升了Web应用的并发处理能力和可用性。
第三章:分布式详解——解耦、协作与复杂性的艺术
如果说集群是解决“量”的问题,那么分布式则是解决“质”和“复杂度”的问题。本章将深入探讨分布式系统的架构、核心挑战和解决方案。
3.1 分布式的核心思想
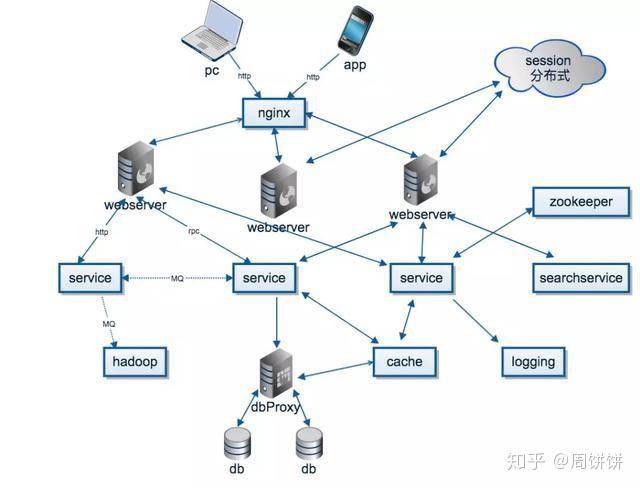
分布式系统的精髓在于将一个大而复杂的问题分解为多个小而简单的问题,并通过服务间的协作来解决。这带来了以下优势:
- 业务解耦: 不同的团队可以独立开发、测试、部署和运维各自负责的服务,大大降低了协作成本和系统复杂度。
- 独立扩展: 可以根据各个服务的实际负载情况,独立地进行水平或垂直扩展。例如,电商大促期间,订单服务压力巨大,可以单独为其扩容,而用户服务可能压力不大,无需扩容。
- 技术异构: 不同的服务可以根据其业务特点选择最适合的技术栈。例如,用户服务用Java,推荐服务用Python(机器学习),实时消息用Go。
- 容错性: 系统的整体可靠性不再依赖于单个组件。一个服务的故障,可以通过熔断、降级、重试等机制进行隔离,避免雪崩效应。
3.2 分布式系统的典型架构
- SOA (Service-Oriented Architecture): 面向服务的架构,是分布式思想的早期实践。它强调将应用功能划分为可重用的服务,通过企业服务总线(ESB)进行集成。ESB承担了服务路由、协议转换、消息转换等复杂功能,但容易成为性能瓶颈和单点故障。
- 微服务架构 (Microservices Architecture): SOA的轻量化演进。微服务倡导将应用拆分为一组小型、独立、松耦合的服务,每个服务围绕一个特定的业务能力构建,可以独立部署、独立扩展。服务间通过轻量级的通信机制(如HTTP/REST、gRPC)进行交互。微服务是当前最主流的分布式架构模式。
- 无服务架构 (Serverless): 更进一步的抽象。开发者只需关注业务逻辑(函数),无需管理服务器。云平台负责函数的运行、伸缩和容错。函数间通过事件触发进行协作,是一种事件驱动的分布式架构。
3.3 分布式系统的关键挑战与解决方案
分布式系统的复杂性主要源于网络的不可靠性。以下是几个核心挑战及其经典解决方案:
3.3.1 挑战一:网络通信的不可靠性
- 问题: 网络延迟、丢包、超时、分区(网络中断)是常态。服务A调用服务B,可能因网络问题导致调用失败或响应延迟。
- 解决方案:
- 超时机制 (Timeout): 为每次远程调用设置合理的超时时间,避免线程无限等待。
- 重试机制 (Retry): 对于幂等操作(多次执行结果相同),可以在调用失败后进行有限次数的重试。但需注意重试风暴。
- 熔断器模式 (Circuit Breaker): 当某个服务的错误率超过阈值时,熔断器会“跳闸”,直接拒绝后续请求,给故障服务恢复的时间。一段时间后,熔断器会尝试半开状态,允许少量请求通过,若成功则关闭,若失败则继续保持打开。常用框架:Hystrix(已归档)、Resilience4j。
- 降级策略 (Degradation): 当非核心服务不可用时,返回默认值、缓存数据或简化逻辑,保证核心功能可用。例如,商品详情页无法获取推荐信息时,显示“暂无推荐”。
3.3.2 挑战二:数据一致性 (Data Consistency)
- 问题: 在分布式环境下,数据通常存储在多个节点上。如何保证这些数据副本之间的一致性,是最大的挑战之一。经典的CAP理论指出,在分布式系统中,一致性 (Consistency)、可用性 (Availability) 和分区容忍性 (Partition tolerance) 三者不可兼得,最多只能同时满足两个。
- 解决方案:
- 强一致性: 通过分布式锁(如ZooKeeper、etcd)或分布式事务(如XA协议、Seata)来实现。但会牺牲性能和可用性。
- 最终一致性: 接受短暂的不一致,通过异步复制、消息队列等方式,最终让所有副本达成一致。这是大多数互联网应用的选择(如MySQL主从复制、Redis主从复制)。常用模式:基于消息队列的事件驱动。
- 共识算法: 用于在多个节点间就某个值达成一致,是分布式协调服务的基础。最著名的算法是Paxos及其简化版Raft(ZooKeeper、etcd、Consul的核心)。Raft通过选举Leader和日志复制来保证数据的一致性和高可用。
3.3.3 挑战三:服务发现与治理
- 问题: 在动态的分布式环境中,服务实例的数量和IP地址是动态变化的(如自动扩缩容)。客户端如何知道要调用哪个服务实例?
- 解决方案:
- 服务注册中心 (Service Registry): 一个中心化的服务目录。服务实例在启动时向注册中心注册自己的信息(服务名、IP、端口、健康状态),在关闭时注销。常用组件:ZooKeeper、etcd、Consul、Eureka。
- 服务发现 (Service Discovery): 客户端或负载均衡器从注册中心查询目标服务的可用实例列表。可以是客户端发现(如Ribbon)或服务端发现(如Consul + Envoy)。
- 服务治理 (Service Governance): 在服务发现的基础上,提供更高级的功能,如负载均衡、熔断、限流、认证授权、链路追踪等。常用框架:Spring Cloud Alibaba (Nacos + Sentinel + Seata)、Dubbo、Istio (Service Mesh)。
3.3.4 挑战四:分布式事务
- 问题: 一个业务操作需要跨多个服务更新数据,如何保证所有操作要么全部成功,要么全部失败?
- 解决方案:
- 两阶段提交 (2PC): 经典的分布式事务协议,由协调者和参与者组成。第一阶段准备,第二阶段提交或回滚。优点是强一致,缺点是同步阻塞、单点故障、数据锁定时间长。
- 三阶段提交 (3PC): 对2PC的改进,引入超时机制和预提交阶段,减少了阻塞,但实现复杂,仍不完美。
- TCC (Try-Confirm-Cancel): 补偿型事务。将一个业务操作拆分为Try(预留资源)、Confirm(确认执行)、Cancel(取消预留)三个阶段。需要业务代码实现这三个接口。优点是性能好、无长期锁,缺点是开发复杂。
- 可靠消息最终一致性: 利用消息队列的可靠投递机制。A服务将操作和消息一起写入本地事务,消息发送到MQ,B服务消费消息并执行操作。通过消息的重试和幂等性保证最终一致性。
- 最大努力通知: A服务执行本地事务后,通过MQ或HTTP等方式通知B服务,B服务收到后执行操作并返回确认。A服务会持续重试通知,直到成功。适用于对一致性要求不高的场景。
第四章:协同与融合——分布式中的集群实践
在真实的生产环境中,分布式与集群往往是紧密结合、协同工作的。一个大型分布式系统,其内部的每一个服务组件都可能是一个集群。
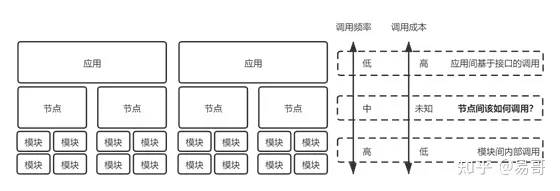

4.1 典型架构:微服务 + 集群
以一个简化的电商平台为例:
- 整体架构是分布式的:
User-Service: 处理用户注册、登录、信息管理。Product-Service: 处理商品信息、库存管理。Order-Service: 处理订单创建、支付、状态流转。Payment-Service: 处理支付流程。- 这些服务通过REST API或gRPC相互通信。
- 局部实现是集群化的:
User-Service因为访问量巨大,部署了5个实例,形成一个集群。前端通过Nginx或API Gateway进行负载均衡。Product-Service部署了3个实例,形成集群。Order-Service在大促期间,从2个实例动态扩容到10个实例,形成更大的集群。- 数据库(如MySQL)采用主从复制,主库处理写请求,多个从库形成集群处理读请求,实现读写分离。
- 基础设施支持:
- 使用 Nacos 或 Eureka 作为服务注册与发现中心。
- 使用 Sentinel 或 Hystrix 实现熔断限流。
- 使用 Seata 管理跨服务的分布式事务。
- 使用 RabbitMQ 或 Kafka 作为消息中间件,实现异步解耦和最终一致性。
- 使用 Prometheus + Grafana 或 SkyWalking 进行监控和链路追踪。
4.2 容器化与编排:云原生时代的集群管理
随着Docker和Kubernetes(K8s)的普及,集群的管理和运维方式发生了革命性变化。
- Docker: 将应用及其依赖打包成轻量级、可移植的容器,解决了“在我机器上能运行”的问题。
- Kubernetes (K8s): 是一个开源的容器编排平台。它能够自动化地部署、扩展和管理容器化应用。在K8s中:
- 一个微服务(Deployment)可以被定义为一个由多个Pod(容器组)组成的集群。
- K8s的Service对象为这个Pod集群提供稳定的网络入口和负载均衡。
- K8s的Horizontal Pod Autoscaler (HPA) 可以根据CPU、内存或自定义指标自动调整Pod的数量,实现动态的集群扩缩容。
- K8s内置了服务发现、健康检查、滚动更新、故障恢复等机制,极大地简化了分布式集群的运维。
可以说,Kubernetes是分布式系统下集群管理的集大成者。
第五章:总结与展望
经过以上万字的深入剖析,我们对分布式与集群有了全面的认识:
- 集群是应对高并发和实现高可用的“量变”手段,它通过复制相同的服务实例来分担负载。
- 分布式是应对复杂业务和提升系统灵活性的“质变”手段,它通过分解业务逻辑来实现解耦和专业化。
- 两者并非对立,而是相辅相成。一个现代的大型系统,必然是一个分布式架构,而其内部的每一个关键服务,又往往通过集群化来保证性能和可用性。
- 分布式系统带来了巨大的优势,但也引入了网络延迟、数据一致性、容错、监控等一系列复杂挑战。掌握服务发现、熔断限流、分布式事务、共识算法等关键技术,是构建健壮分布式系统的必备技能。
- 以Docker和Kubernetes为代表的云原生技术,正在重塑分布式集群的构建和管理模式,让开发者能更专注于业务逻辑,而将复杂的基础设施管理交给平台。
未来,随着边缘计算、AI大模型、物联网等技术的发展,分布式系统的规模和复杂度将进一步提升。理解分布式与集群的本质,掌握其核心原理和实践方法,将成为每一位软件工程师不可或缺的核心能力。
最后,记住那句经典的话:“分布式中的每一个节点,都可以做集群。而集群并不一定就是分布式的。” 理解了这句话,您就真正掌握了分布式与集群的精髓。
超融合分布式系统讲解视频
发表评论